

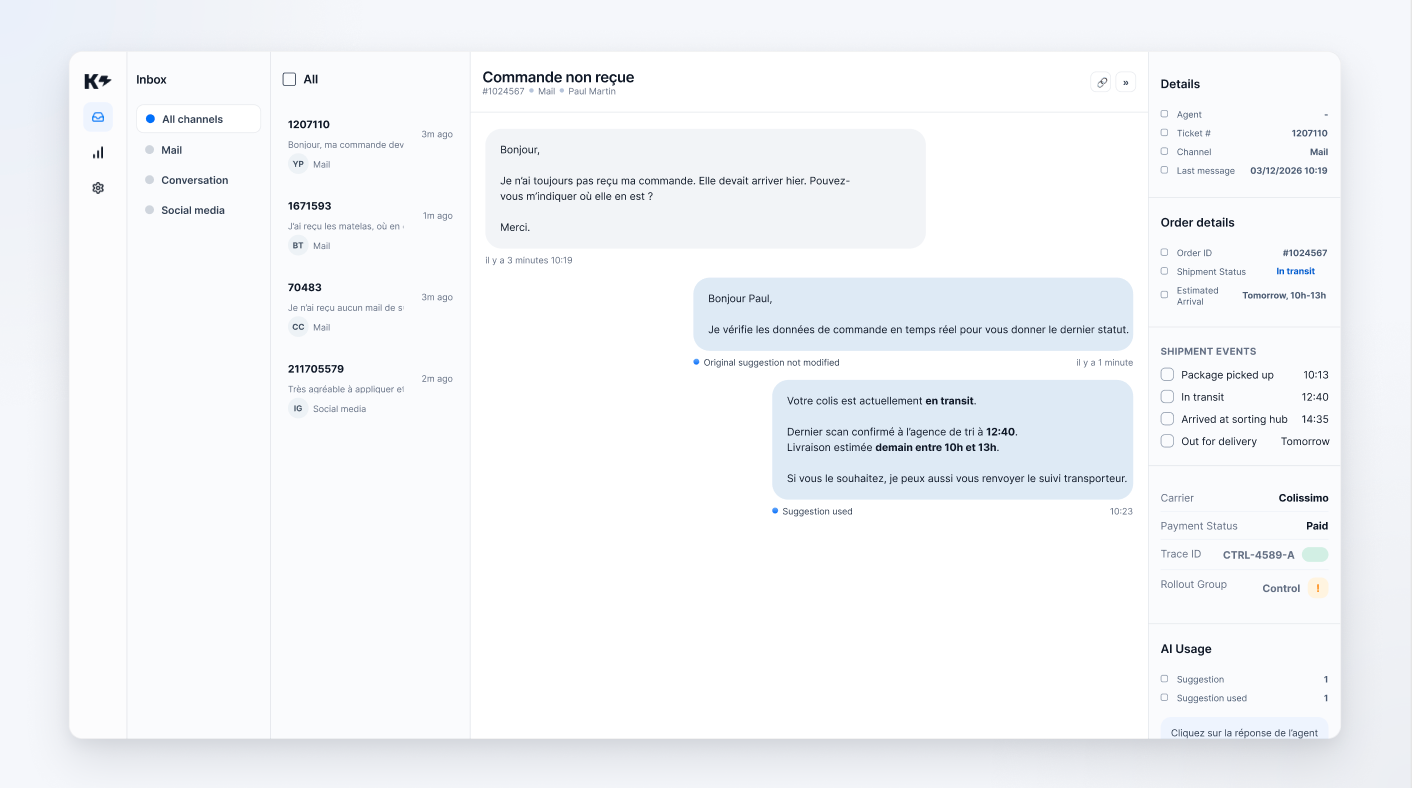
A customer writes to support: "Where is my order?"
In a demo, an agentic AI quickly impresses. It understands the question, calls a real-time source, retrieves the order status, and responds in seconds with a clean answer.
In production, it's rarely that simple.
The data may be incomplete. The customer context may be missing. The model may call this capability when it does not need it. Or, even more subtly, this real-time access may be active but degrade performance instead of improving it if the scope, prompts, or data are not clean enough.
This is where many teams go wrong. The question is not simply "Can AI take action?" The real question is: In what context can it take action, what are its limitations, and how do we know that it truly improves customer service?
In this article, we start with a very concrete case: a customer service assistant capable of retrieving order data in real time. We draw on real-world learning, not just demos: gradual activation, A/B testing, analysis bias, technical safeguards, and observability.
If you're looking to deploy agentic AI in customer service, that's usually where the game is played.
Key points in 3 sentences:
A demo is successful because it takes place in a clean environment. The case is simple. The data is ready. The context is known. The tool responds well. And no one asks what happens when the API call fails, when the client is not recognized, or when the AI loops.
Production, on the other hand, raises much more demanding questions.
Is the tool activated for all customers or only for certain ones? Does the model know when to call on this capability, and more importantly, when not to call on it? What happens if the external data is noisy, partial, or contradictory? How do we measure whether it actually improves responses? And how do support teams verify what the AI has done?
As long as these questions remain unclear, we don't have a production system. We have a nice demonstration.

Let's take a simple and common case in customer service: "WISMO" (Where Is My Order) requests.
When a customer asks about the status of their package, a traditional chatbot often gives a generic response or provides a tracking link. An agentic AI that is well connected to real-time order data ( for example, with tools such as Shopify, OneStock, PrestaShop, or others) can do something else.
She can check the status, logistics events, tracking ID, or certain amounts, then tailor her response to the customer's exact situation.
On paper, it's exactly what you'd expect.
In real life, just because a capability exists does not mean that performance immediately follows.
We often see this in practice: initially, results may be lower than expected, or even worse than a version without real-time access. This is not because the idea is bad, but because an agentic system depends on the entire chain around it:
All these parameters have a direct impact on AI deliverables.
In other words, real-time access capability alone does not create performance. It creates a possibility. Performance comes from the complete system.
A common mistake is to activate this capability across the entire perimeter at the same time.

In practice, serious deployment is almost always done gradually. In a case such as real-time access to commands, access to this feature depends on an explicit configuration transmitted to the model, via logic such as availableToolsThis allows certain capabilities to be enabled or disabled depending on the customer, scope, or launch phase.
This point is much more important than it seems.
You can test the feature on a subset of customers. You can limit the fields exposed to only those that are strictly necessary. You avoid making a feature that is still unstable available everywhere. And you can make corrections before rolling it out to everyone.
In customer service, this is essential. An agentic AI in production is not deployed "all at once." It is deployed customer by customer, segment by segment, with a ramp-up approach.
This is also how you avoid drawing the wrong conclusions. If you activate everything everywhere immediately, you can no longer distinguish between a prompt problem, a data problem, a test group quality problem, or a real problem with the functionality itself.
A good agentic AI does not call a real-time source for every message.
If the customer asks, "What are your hours?", calling order access makes no sense. If the customer asks, "My package was supposed to arrive yesterday, where is it?", not calling this feature is usually a mistake.
The value of agentic AI lies here: the model reads the context of the conversation, determines whether it needs external data, and then decides whether or not to call a real-time access such as fetch_orders.
This behavior changes everything compared to a fixed workflow.
But this autonomy is only useful if it remains regulated. Otherwise, the result is a costly, unpredictable system that may even be less effective than a simpler approach.
So the right question is not "Should we let the model decide?" The right question is: under what conditions does its decision become sufficiently reliable, measurable, and reversible to be acceptable in production?
This is probably the least intuitive point, yet one of the most important.
In practice, a newly connected agentic capability does not always immediately outperform existing systems. Initially, it may even perform worse than a system without real-time access.
Why? Because between theoretical capacity and actual performance, there are several layers that need to be stabilized:
Without this work, there is a risk of jumping to the conclusion that "the functionality doesn't work," when the real issue lies elsewhere, for example in data cleaning or a biased evaluation framework.
That's why a successful agent deployment often relies on A/B testing, partial launches on a fraction of traffic, prompt iterations, tool scope adjustments, and a careful review of cases where the capacity helped, failed, or was called unnecessarily.
This work is less spectacular than a demo. But it is what creates the production tool.
Some signals to prioritize:
When talking about AI safeguards, we need to move beyond vague rhetoric.
In a real agentic system, useful protections are concrete: iteration limits to avoid loops, detection of repeated calls with the same input, API-side timeouts, structured errors rather than silent failures, and blocking if the minimum client context is missing.
In the case of real-time access to order data, this means, for example:
It is these details that transform an agentic capability into an exploitable capability. An agentic production AI does not need to be perfect. Above all, it must be bounded, predictable, and stoppable.
Agentic AI that acts without leaving a trace creates more concern than value.
For a system to be governable, it must be possible to answer simple questions: which capacity was called, for which ticket, in what context, how many times, and with what result.
In a clean design, this involves several levels of traceability:
tools_used or tool_calls_count.This is not a topic reserved for developers.
For customer service teams, this observability makes it possible to understand why a response was generated, audit sensitive cases, distinguish between responses based on real data and purely generative responses, and prioritize real deployment issues.
A support team doesn't trust AI because it "seems smart." It trusts it because it can verify what it has done.
Seen from a distance, agentic AI appears to be a technical issue. In reality, it quickly becomes a matter of operational management.
When the framework is well designed, responses become more accurate regarding orders, deliveries, and refunds. Deployment can be done gradually. Risks become more transparent. And teams better understand when AI truly helps.
Above all, the conversation is changing. We are no longer just discussing "agentic AI" as a concept. We are finally talking about the real issues: when to activate it, how to measure it, how to correct it, and how to know if it brings more benefits than complications.
That is exactly what distinguishes a marketing promise from a production rationale.
At Klark, we don't view agentic AI as a mere demonstration effect.
The real challenge is to help support teams save time and respond more accurately using their usual tools. This requires a much more operational approach: connecting the right sources of truth, exposing the right capabilities at the right time, limiting autonomy when the context is insufficient, measuring results on real cases, and evolving the system based on what is actually happening in production.
That's why rollout, safeguards, and observability are so central to Klark. They may be less visible than a demo, but they're much closer to the real life of customer service.
To learn more about this topic, you can also read our article on agentic AI for customer service, our article on Agentic RAG applied to customer service, and our Solutions page.
Deploying agentic AI in production is not about plugging a model into a real-time source and hoping for the best.
The real work involves activating the right capability at the right scope, supervising the model's decisions, limiting deviations, honestly measuring performance, and accurately understanding what the AI has done.
In customer service, it is this discipline that makes the difference between AI that is impressive in demonstrations and AI that is truly useful on a daily basis.
About Klark
Klark is a generative AI platform that helps customer service agents respond faster and more accurately, without changing their tools or habits. Deployable in minutes, Klark is already used by more than 60 brands and 2,000 agents.





