

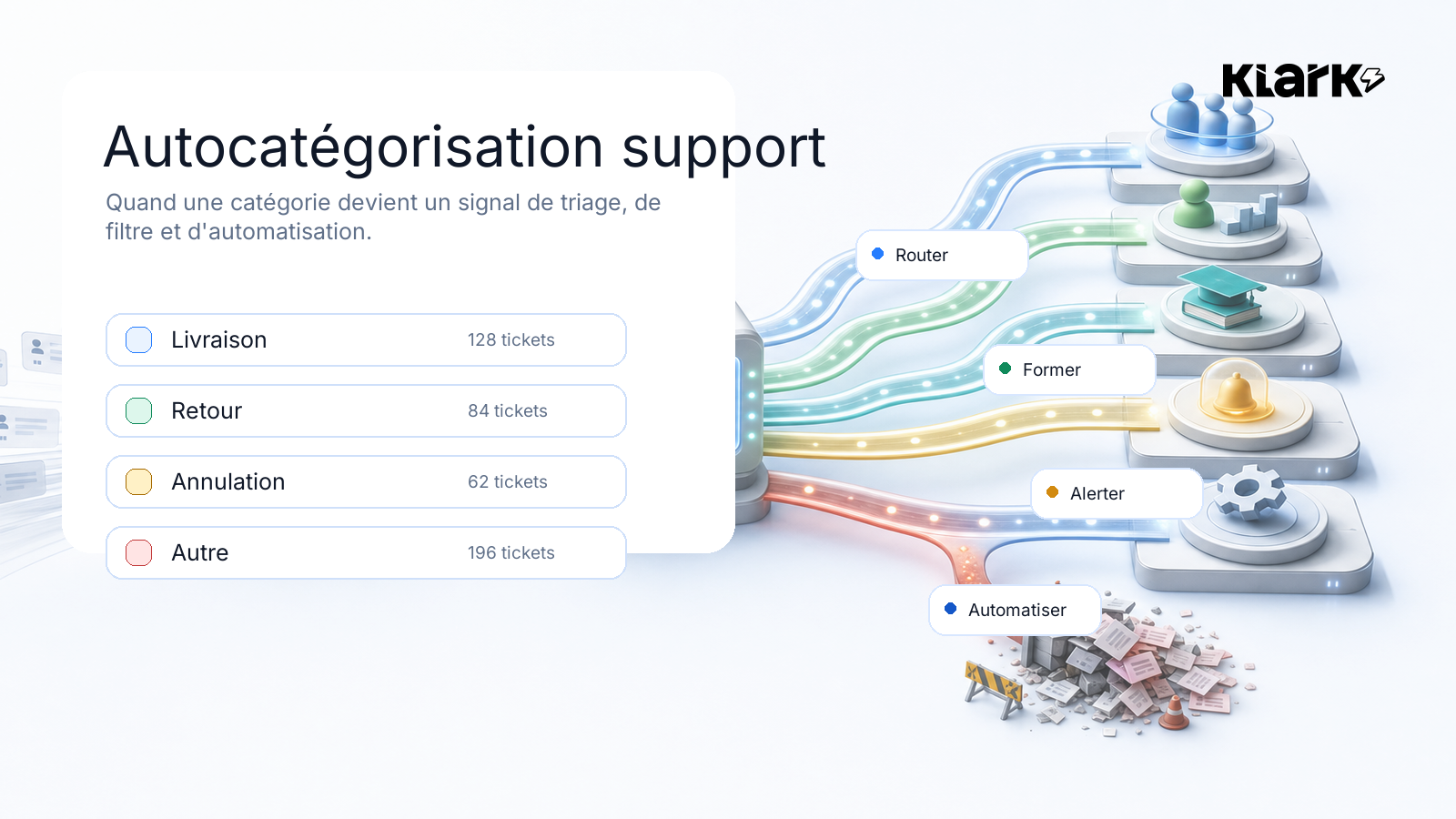
Une catégorie support n'est jamais juste une case à cocher.
Au début, elle sert à ranger les tickets. Puis elle commence à décider ce qu'on peut router, filtrer, former, prioriser ou automatiser.
C'est là que l'autocatégorisation devient un sujet sérieux : si le signal est flou, toute l'opération derrière devient floue.
Beaucoup d'équipes traitent la catégorisation comme une affaire de reporting.
Elles veulent savoir combien de tickets parlent de livraison, combien parlent de retour, combien parlent de paiement, combien finissent dans un motif résiduel.
C'est utile. Mais c'est trop petit.
Dans un service client moderne, une catégorie ne sert pas seulement à ranger le passé. Elle commence à décider ce que vous pouvez faire ensuite.
• Elle peut aider à router un ticket.
• Elle peut aider à répartir la charge du matin.
• Elle peut donner des cas simples à des agents en montée en compétence.
• Elle peut expliquer pourquoi un sujet monte.
• Elle peut filtrer une base de connaissance.
• Elle peut exclure certains cas de l'automatisation.
• Elle peut, demain, ouvrir ou fermer le droit à une réponse automatique.
C'est pour ça qu'une mauvaise catégorie ne casse pas seulement un dashboard. Elle peut casser le triage, l'automatisation et la confiance des agents.
Les derniers retours clients autour de l'autocatégorisation racontent tous la même chose : le sujet n'est pas magique, il est très opérationnel.
Chez IZIPIZI, le retour est clair : certaines demandes d'annulation se retrouvent dans des procédures de retour, des demandes d'annulation peuvent apparaître dans Erreur de préparation, et Autre récupère trop de cas qui devraient être mieux séparés.
C'est exactement le genre de signal qui paraît petit, mais qui change tout.
Parce qu'une catégorie trop large donne une impression de contrôle. En réalité, elle masque le travail à faire.
Chez Le Temps des Cerises, le sujet était différent : des niveaux 1 et niveaux 2 se dupliquaient, certaines formulations étaient trop internes côté outil ou API, et il a fallu nettoyer l'arbre pour que les intentions restent compréhensibles par l'algorithme.
Chez Bonsoirs, l'équipe a ajouté des catégories comme Spam / Publicité, Réponse automatique et Partenaires / emails internes, puis remis à jour un arbre avec 31 catégories actives.
Ce n'est pas un détail cosmétique.
C'est le moment où une taxonomie support commence à devenir exploitable.
Le piège classique arrive quand la catégorie est pensée uniquement pour le reporting.
On veut tout comprendre.
Donc on veut tout mesurer.
Donc on crée des catégories pour chaque nuance : le motif, le sous-motif, le cas limite, le cas rare, le cas qui servira peut-être un jour dans un comité mensuel.
Sur le papier, c'est rassurant. Dans la vraie vie, ça produit un arbre que personne n'utilise correctement.
On a déjà vu des arbres avec environ 70 catégories. C'est lourd pour un humain. C'est aussi lourd pour une machine, parce que beaucoup de catégories finissent par se recouvrir.
Pour un agent, le résultat est prévisible : il faut choisir vite, dans une liste trop longue, pour nourrir un reporting dont l'utilité n'est pas toujours claire.
Et quand la liste fatigue, le syndrome du premier item arrive.
L'agent ne sait pas vraiment quoi choisir. Il est pressé. La catégorisation lui semble administrative. Il clique sur le premier choix plausible, ou sur Autre, et passe au ticket suivant.
La machine a un avantage très simple : elle ne se lasse pas. Elle ne catégorise pas moins bien à 18h parce que la journée a été longue. Elle ne choisit pas le premier item parce qu'on l'a forcée à remplir un champ.
Mais cet avantage ne vaut que si on lui donne une taxonomie faite pour agir, pas un arbre de reporting obèse.
Tant que les catégories ne servent qu'à lire un dashboard, leur précision est importante, mais pas critique.
Dès qu'elles servent à déclencher ou bloquer des actions, le niveau d'exigence change.
Un ticket catégorisé trop large peut être mal routé.
Un ticket qui n'est pas une vraie demande support peut disparaître d'une lecture utile s'il est mal isolé.
Une demande sensible peut rentrer dans un périmètre d'automatisation qui aurait dû l'exclure.
Un motif mal nommé peut être incompris par l'algorithme, puis corrigé à la main par les agents, puis perdre toute crédibilité.
C'est là que le sujet devient très concret pour Klark.
Les catégories ne sont pas seulement une sortie d'analyse. Elles deviennent progressivement une entrée de décision.
Et c'est précisément ce qu'on voit dans les sujets produits récents : fiabiliser les raisons de contact envoyées dans le helpdesk, éviter qu'une question tronquée provoque une mauvaise catégorisation, clarifier quel signal sert aux règles d'autoreply, puis décider quels motifs peuvent être inclus ou exclus d'une automatisation.
Dit simplement : si la catégorie devient un signal d'action, elle doit être fiable.
Pour une équipe support exigeante, le sujet n'est donc pas seulement de brancher un bot. Le vrai sujet est de savoir quels signaux on accepte de laisser piloter le triage, les exclusions et l'automatisation.
On parle beaucoup de modèle. On devrait parler plus souvent de taxonomie.
Une mauvaise taxonomie donne au modèle un mauvais terrain de jeu.
• Si deux catégories se recouvrent, l'IA hésite.
• Si les intitulés sont trop internes, elle se trompe.
• Si Autre sert de poubelle, elle y mettra trop de choses.
• Si les niveaux 1 et 2 sont incohérents, les agents ne sauront plus si le problème vient de Klark, du helpdesk, ou de l'arbre de départ.
Le bon travail est moins spectaculaire : nommer proprement, séparer les cas qui doivent l'être, garder des catégories actionnables, supprimer les doublons, vérifier ce que les agents corrigent.
Ce n'est pas le chantier le plus visible d'un projet IA. Mais c'est souvent là que se joue la qualité réelle.
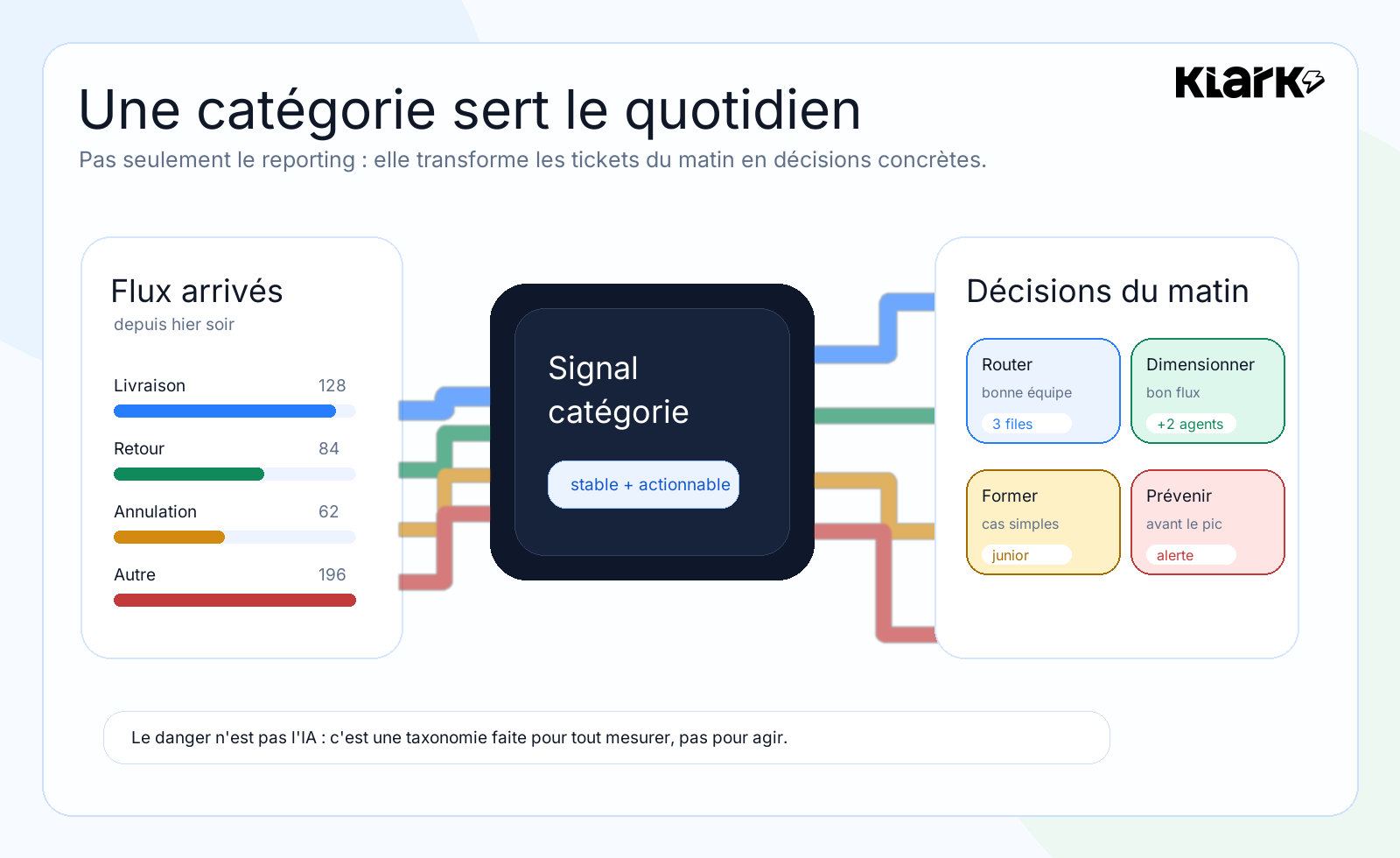
La valeur se voit très vite dans une routine support.
Le matin, un manager n'a pas seulement besoin de savoir combien de tickets sont arrivés.
Il a besoin de comprendre ce qui a changé.
Est-ce qu'un flux livraison a explosé pendant la nuit ?
Est-ce qu'il faut mettre plus de monde sur les retards de commande ?
Est-ce qu'un incident transporteur mérite une communication proactive avant que la file ne déborde ?
Est-ce que les demandes simples peuvent être données à une personne en montée en compétence, pendant que les agents seniors gardent les cas sensibles ?
Est-ce qu'un motif est assez stable pour déclencher une macro, une suggestion, un filtre ou une automatisation ?
Dans cette lecture, la catégorie n'est plus une colonne de reporting. C'est un signal de travail quotidien.
• Elle aide à trier.
• Elle aide à dimensionner l'équipe.
• Elle aide à former.
• Elle aide à prévenir.
• Elle aide à automatiser seulement quand le terrain est assez propre.
Une question client récente est très saine : est-ce qu'on mesure le taux de succès de la catégorisation ? Autrement dit, combien de fois la catégorie fournie par Klark reste inchangée par l'agent ?
C'est une excellente question.
Parce que le vrai sujet n'est pas seulement : est-ce qu'une catégorie a été poussée ?
Le vrai sujet est plutôt :
• est-ce que l'agent l'a gardée ?
• est-ce qu'il l'a corrigée ?
• est-ce que certaines catégories sont corrigées plus souvent que d'autres ?
• est-ce que Autre absorbe des cas qui devraient être nommés ?
• est-ce que la catégorie permet vraiment d'agir ?
Ce genre de métrique change la discussion.
On ne regarde plus seulement une production automatique. On regarde une confiance opérationnelle.
L'automatisation support est tentante.
Surtout quand les volumes montent, que les tickets simples reviennent, et que les agents passent trop de temps à répéter les mêmes réponses.
Mais automatiser sur une catégorie fragile, c'est ouvrir la porte trop tôt.
Si vous ne savez pas distinguer proprement une demande d'annulation d'une demande de retour, vous n'êtes pas encore prêt à décider automatiquement quoi faire sur ce périmètre.
Si les spams, réponses automatiques et emails internes contaminent votre arbre, vous allez mesurer du bruit.
Si vos agents corrigent souvent la même catégorie, le système vous dit déjà quelque chose : la catégorie n'est pas encore assez fiable pour servir de règle.
C'est là que le lien avec l'automatisation devient intéressant. Une bonne IA support ne doit pas juste répondre plus vite. Elle doit savoir quand ne pas répondre, quand exclure, quand escalader, et quand laisser un humain garder la main.
L'autocatégorisation est l'un des signaux qui permet de faire cette différence.
Chez Klark, le sujet n'est pas de produire une belle colonne en plus dans un export.
Le sujet est de rendre les flux entrants plus lisibles et plus actionnables.
D'abord pour les équipes support : mieux comprendre ce qui arrive, corriger les catégories faibles, réduire le flou autour des motifs.
Ensuite pour les managers : voir où se concentrent les irritants, où les agents corrigent, où les volumes changent vraiment.
Enfin pour l'automatisation : ouvrir certains périmètres seulement quand le signal est assez propre.
C'est exactement l'ordre qui évite de vendre un grand soir automatique.
On part du terrain. On structure le signal. On vérifie la confiance. Puis on automatise ce qui peut l'être.
L'autocatégorisation n'est pas un détail de reporting.
C'est une couche d'infrastructure opérationnelle.
Si elle est mauvaise, elle brouille la lecture du support. Si elle est bonne, elle aide à comprendre, prioriser, filtrer et automatiser plus intelligemment.
La différence se voit rarement dans une démo.
Elle se voit dans les cas pénibles : Autre qui gonfle, agents qui corrigent, catégories qui se chevauchent, champs helpdesk qui ne poussent pas, règles d'autoreply qui ont besoin d'un signal fiable.
C'est là que le sujet devient sérieux.
Une automatisation support fiable commence souvent par une question moins brillante, mais beaucoup plus utile :
est-ce que nos catégories disent vraiment ce qui se passe ?
Vos catégories support servent vraiment à piloter ?
Klark aide les équipes support à structurer les flux entrants, fiabiliser les motifs et ouvrir l'automatisation sur les bons cas.




